

How To Catch Malware Using Spark
May 18, 2020
Building a Data Pipeline with Apache NiFi
June 15, 2020ksqlDB is an event streaming database that enables creating powerful stream processing applications on top of Apache Kafka by using the familiar SQL syntax, which is referred to as KSQL. This is a powerful concept that abstracts away much of the complexity of stream processing from the user. Business users or analysts with SQL background can query the complex data structures passing through kafka and get real-time insights. In this article, we are going to see how to set up ksqlDB and also look at important concepts in ksql and its usage.
Reasoning behind the evolution of KSQL
Apache Kafka is the most popular open source stream processing software that helps to provide unified, high throughput and low latency platforms for transporting and handling real-time feeds. Stream analytics is a method to analyze the streams as it flows through kafka using the business logic and gather real-time insights.
Some of the applications could be real-time monitoring operations dashboards showing KPIs, purchasing behaviour of the customers to send promotional offers to their home for purchasing frequently, loyalty rewards if the customer has exceeded a threshold of shopping for a specific number of times in a time window and much more.
Apache Kafka Streams (written in Java or Scala) was quite popular in building streaming analytics applications but it requires programming knowledge and hence quite distant for folks who would want to use SQL. KSQL bridges this gap by exposing a familiar SQL interface, which can be used by a widespread audience, but behind the scenes it converts the KSQL to Kafka streams application automatically and does all the hard work.
Interested in Kafka? check out our Hadoop Developer In Real World course for interesting use case and real world projects in Kafka
Reference Architecture
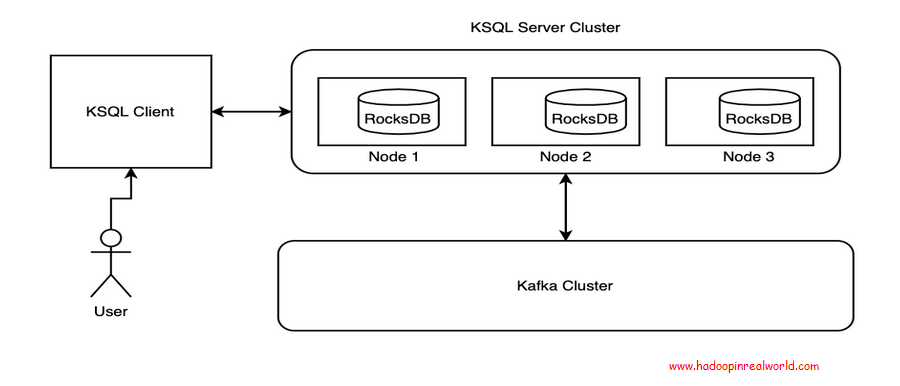
The KSQL Client provides a command line interface to interact with KSQL Server Cluster. The KQL Server manages interaction with the kafka topic to get the events as and when it gets produced and reaches kafka. The state store is maintained inside each node where the states are maintained based on the key and gets distributed across nodes. We will learn about each of those components throughout the remainder of the sections.
Example Environment Set up
First step in starting to use ksqlDB is to set it up on your local machine.
- Visit https://www.confluent.io/product/ksql/ and download the confluent platform.
- Download confluent command line interface: curl -L https://cnfl.io/cli | sh -s — -b <confluent installed bin directory: example – /opt/confluent/bin>
- Make sure the installed bin directory is added to $PATH.
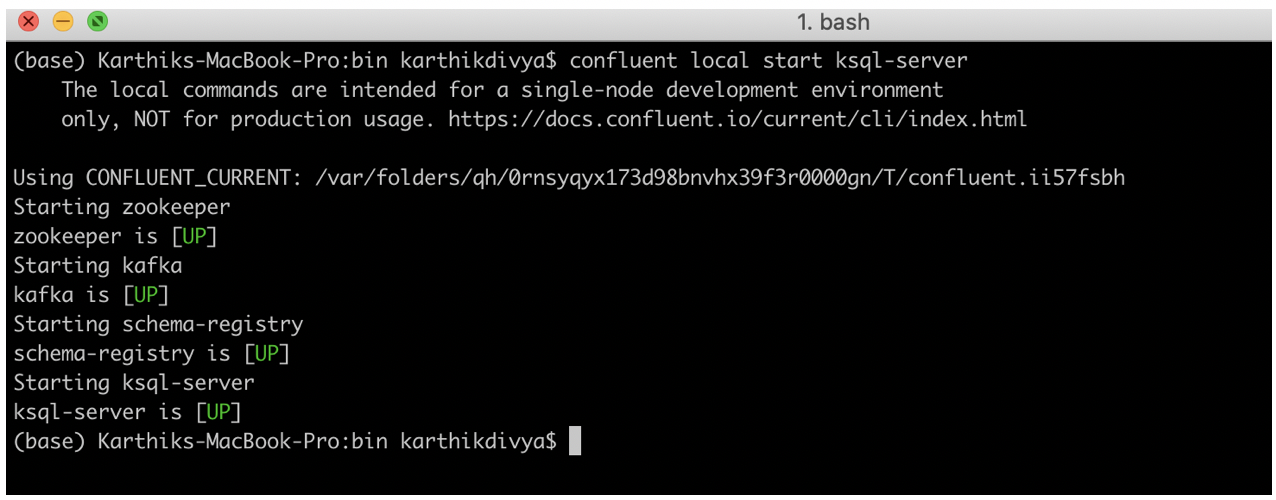
- Once successfully installed, type confluent in terminal and you should see below

Once the above steps are completed, you are all set to continue your adventure with ksqlDB. The confluent server can be started using the command: confluent local start ksql-server
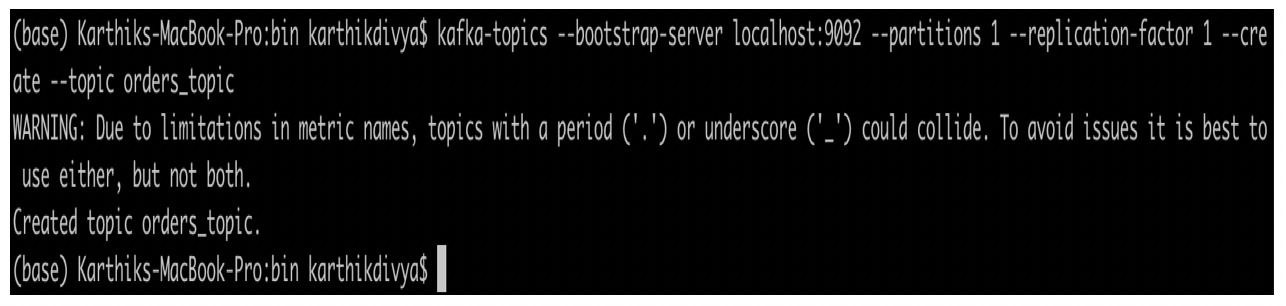
Sample command to create a new kafka topic
kafka-topics --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1 --create --topic orders_topic
KSQL-Datagen
KSQL-Datagen is a powerful data generator utility that is shipped with the confluent platform that was downloaded in the above section. This helps to create data based on the schema defined by us and this would be a helpful tool to generate random data for development and testing.
For the rest of the article, we are going to be looking at two data sets – orders and customers.
Let’s imagine that we own an online retail store where orders are getting placed continuously and the details that we capture are below (for simplicity). Order information contains unique-id of the order , customer name, date of purchase ( unix timestamp format), total amount and number of items purchased.
{"id":1009,"customername":"Peter","date":1588907310,"amount":1144.565,"item_quantity":26}
The customer information that is captured as below. The customer information contains customer name, country and customer status.
{"customername":"Peter", "country": "AUSTRALIA", "customer_type": "PLATINUM"}
Data Loading
We can use the below ksql-datagen command to generate the orders for us:
ksql-datagen schema=./blog/datagen/orders.avro format=avro topic=orders key=id maxInterval=5000 iterations=10
Parameters to the command are explained below:
Schema: Schema to refer to to generate data Format: Format of the output Topic: Topic to produce data to Key: Key for the data MaxInterval: Frequency interval between each data generated Iterations: Number of records to generate.

Code & Dataset
The code, commands and queries used in this post are available in the github link here
The commands.md file contains all the commands, code and queries used throughout this article. The blog/datagen folder contains orders.avro and customers.avro schema files that are used while the ksql-datagen utility tries to generate the sample data. Please feel free to manipulate the schema to generate different records.
If you are enjoying this post, you may also interested in learning about Kafka Schema Registry & Schema Evolution
Streams
ksqlDB has the concept of streams. ksqlDB operates on the underlying kafka topic and the data that comes through that. Streams can be thought of as the layer that is spread on top of the kafka topic with the defined schema of the data that is expected in the topic. Once this stream is registered with ksqlDB, we can start querying the stream with KSQL syntax and start gathering insights from it.
Create a topic with the name “orders”
kafka-topics --zookeeper localhost:2181 --partitions 1 --replication-factor 1 --create --topic orders

Type “ksql” from command line to launch ksql client. You should see the ksql> prompt as below and then type the below command to see the list of topics
list topics;

Create a stream with the name “orders_stream” with the following command
CREATE STREAM orders_stream(id INT, customername VARCHAR, date BIGINT, amount DOUBLE, item_quantity INT) WITH (VALUE_FORMAT='JSON', KAFKA_TOPIC='orders')

In ksql prompt, type “list streams;” to see the list of streams that are currently available.

The “CREATE STREAM” command is used to register the stream with the specified schema and it also mentions the topic that the stream must listen to. Once it is all set up, we can start spinning some ksql queries on top of it to listen to real-time analytics !
Why don’t we spin up the below query to identify the aggregated order information in terms of total purchase amount per customer and the number of items purchased each day. This will give us some real-time insights on customer purchases and we can probably offer some on the spot discounts!!
SELECT customername,TIMESTAMPTOSTRING(date, 'dd/MMM') AS purchase_date, SUM(amount) AS total_amount, SUM(item_quantity) FROM orders_stream GROUP BY customername, TIMESTAMPTOSTRING(date, 'dd/MMM') emit changes;

As you can see, the above ksql query resembles the typical SQL query that we use for querying relational tables. One change would be the “emit changes” in syntax. From the recent version of the confluent platform, it is necessary to use “emit changes” as a part of the syntax. All queries must end with a semicolon.
In ksql prompt, type the aforementioned ksql query
Let us take the help of our ksql-datagen to generate some data to our orders topic
ksql-datagen schema=./blog/datagen/orders.avro format=json topic=orders key=id maxInterval=5000 iterations=10

Tables
Having looked at the streams in the previous section, it would be the right time to look at Tables in ksql. Yes, it does mean the same thing as the relational tables. The tables are used to store state information in ksqlDB’s built in database – RocksDB. RocksDB persists data on the disk in a local queryable format. The data that gets persisted will be available and distributed across all nodes in the ksql cluster based on the key. So, data will not be deleted or removed once the messages/events get emitted from the underlying kafka topic. To look at the directory where the data is persisted, type “list properties;” in ksql prompt and navigate to the property – ksql.streams.state.dir. This is the directory in which the state information is persisted. Never manipulate this directory as it may potentially corrupt the database.

By using tables, we can make stateful queries that can look up on the table to get additional information to provide greater insights as the data flows through the topic continuously.
We have the customer information with us. Let us assume the customer status, which could either be SILVER, GOLD and PLATINUM, changes continuously based on the purchasing behaviour and we want to maintain the state information in a table.
Let us start the drill with creating topic
kafka-topics --zookeeper localhost:2181 --partitions 1 --replication-factor 1 --create --topic customers

Type “list topics; ” in ksql prompt to list the topics available in ksqlDB.
The “CREATE TABLE” command is used to create tables and the command looks similar to the CREATE STREAM command but it is better to mention row key in the table creation command to be explicit. Remember, the row key should match with one of the columns present.
CREATE TABLE customer_table(customername VARCHAR, country VARCHAR, customer_type VARCHAR) WITH (VALUE_FORMAT='JSON', KAFKA_TOPIC='customers', KEY='customername');

Type the below in ksql prompt
SELECT customername, country, customer_type from customer_table emit changes;

Let us use our ksql-datagen to fire up some customer data for us and spin up ksql query to listen to that data.
ksql-datagen schema=/Users/karthikdivya/Desktop/Personal/Udemy/KSQL/blog/datagen/customers.avro format=json topic=customers_topic_test key=customername maxInterval=10000 iterations=10

As you start sending the data generated through the ksql-datagen to the topic, the table should start showing the information.The state information gets continuously persisted in the table based on the rowkey that can be queried anytime.
Interested in Kafka? check out our Hadoop Developer In Real World course for interesting use case and real world projects in Kafka
Streams vs. Tables
The typical question that arises at this point would be when to use what as both looks syntactically similar. Both streams and tables are wrappers around the kafka topic as you have witnessed. We created a kafka topic and pushed the messages through it for it to be consumed via streams or tables.
Streams are unbounded and immutable. They operate on continuous flow of data in the kafka topic and the new data gets continuously appended to the stream and the existing records are not modified. In other words, streams operate on data at motion. A typical use case would be to power the operational dashboard real-time and keep it updated with the new events.
Tables are bounded and mutable. They operate on data at rest with the row key of the table getting updated with the latest value from the events coming through in the kafka topic. If the key is already present then the value gets updated, otherwise the new key will be inserted into the table.
Joins
We saw both streams and tables and how we are able to write powerful aggregate queries on the streaming data to get powerful insights on the go. One of the most powerful features in SQL is JOINS. JOINS lets us relate multiple tables together that will be needed to get richer information. What use will it be if we do not have the ability to JOIN in ksql ? Fortunately, we do not have to worry as we have one in KSQL.
Let us join our stream and table together and emit the combined information out. By that we will be able to get the location and customer status as well along with the order information.
Ksql query that joins orders stream and customer table
SELECT customer.customername, customer.country, customer.customer_type as customer_status,TIMESTAMPTOSTRING(order.date, 'dd/MMM') AS purchase_date, SUM(order.amount) as total_amount, SUM(order.item_quantity) as total_quantity FROM orders_stream as order LEFT JOIN customer_table as customer ON order.customername = customer.customername GROUP BY customer.customername, customer.country, customer.customer_type, TIMESTAMPTOSTRING(order.date, 'dd/MMM') emit changes;

Let us start our orders stream and push some data to it through ksql-datagen using the similar command as before:
ksql-datagen schema=/Users/karthikdivya/Desktop/Personal/Udemy/KSQL/blog/datagen/orders.avro format=json topic=orders key=id maxInterval=5000 iterations=10
Like what you are reading? You would like our free live webinars too. Sign up and get notified when we host webinars =>
Conclusion
The article should have given you a good overview around the fit of ksql, the applications, set up and important concepts and constructs. The post is practice heavy and I would highly recommend you to follow the github link to download the code to try out on your own using different datasets to get a good understanding. Overall, KSQL is pretty popular in the streaming analytics space and it has a wide variety of built-in functions. I would highly recommend you all to take a look into the official confluent documentation on KSQL – https://docs.confluent.io/4.1.0/ksql/docs/index.html#ksql-documentation

