
What is the difference between Hive internal tables and external tables?
January 20, 2021How to control log settings in Spark and stop INFO messages?
January 25, 2021Shuffle Sort Merge Join, as the name indicates, involves a sort operation. Shuffle Sort Merge Join has 3 phases.
Shuffle Phase – both datasets are shuffled
Sort Phase – records are sorted by key on both sides
Merge Phase – iterate over both sides and join based on the join key.
Shuffle Sort Merge Join is preferred when both datasets are big and can not fit in memory – with or without shuffle.
Do you like us to send you a 47 page Definitive guide on Spark join algorithms? ===>
Example
spark.sql.join.preferSortMergeJoin by default is set to true as this is preferred when datasets are big on both sides.
Spark will pick Broadcast Hash Join if a dataset is small. In our case both datasets are small so to force a Sort Merge join we are setting spark.sql.autoBroadcastJoinThreshold to -1 and this will disable Broadcast Hash Join.
scala> spark.conf.get("spark.sql.join.preferSortMergeJoin")
res1: String = true
scala> spark.conf.get("spark.sql.autoBroadcastJoinThreshold")
res2: String = -1
scala> val data1 = Seq(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50)
data1: Seq[Int] = List(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50)
scala> val df1 = data1.toDF("id1")
df1: org.apache.spark.sql.DataFrame = [id1: int]
scala> val data2 = Seq(30, 20, 40, 50)
data2: Seq[Int] = List(30, 20, 40, 50)
scala> val df2 = data2.toDF("id2")
df2: org.apache.spark.sql.DataFrame = [id2: int]
scala> val dfJoined = df1.join(df2, $"id1" === $"id2")
dfJoined: org.apache.spark.sql.DataFrame = [id1: int, id2: int]
When we see the plan that will be executed, we can see that SortMergeJoin is used.
scala> dfJoined.queryExecution.executedPlan res3: org.apache.spark.sql.execution.SparkPlan = *(3) SortMergeJoin [id1#3], [id2#8], Inner :- *(1) Sort [id1#3 ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id1#3, 200) : +- LocalTableScan [id1#3] +- *(2) Sort [id2#8 ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id2#8, 200) +- LocalTableScan [id2#8] scala> dfJoined.show +---+---+ |id1|id2| +---+---+ | 20| 20| | 20| 20| | 20| 20| | 20| 20| | 20| 20| | 20| 20| | 40| 40| | 40| 40| | 50| 50| | 30| 30| +---+---+
Stages involved in Shuffle Sort Merge Join
As we can see below a shuffle is needed with Shuffle Hash Join. First dataset is read in Stage 0 and the second dataset is read in Stage 1. Stage 2 below represents the shuffle.
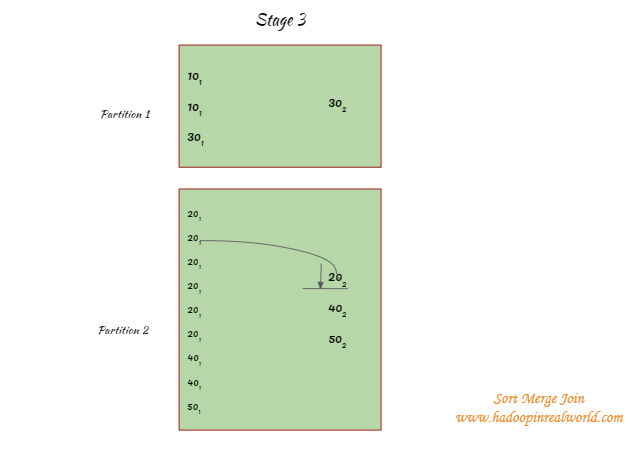
Inside Stage 2 records are sorted by key and then merged to produce the output.

Internal workings for Shuffle Sort Merge Join
There are 3 phases in a Sort Merge Join – shuffle phase, sort phase and merge phase.
Shuffle phase
Data from both datasets are read and shuffled. After the shuffle operation, records with the same keys from both datasets will end up in the same partition after the shuffle. Note that the entire dataset is not broadcasted with this join. This means the dataset in each partition will be in a manageable size after the shuffle.
Sort phase
Records on both sides are sorted by key. Hashing and bucketing are not involved with this join.
Merge phase
A join is performed by iterating over the records on the sorted dataset. Since the dataset is sorted the merge or the join operation is stopped for an element as soon as a key mismatch is encountered. So a join attempt is not performed on all keys.
For eg. in partition 2 when keys are attempted to match for 201 records are iterated through on the other side up until 402 is reached as the records are sorted there is no need to iterate through the entire records on the other side.
When does Shuffle Sort Merge Join work?
- Works only on equi joins
- Work on all join type
- Works on big datasets
- Both shuffle and sort on keys are involved with this join.
When Shuffle Sort Merge Join doesn’t work?
- Doesn’t work on non equi joins.
- Both shuffle and sort are expensive operations. Use this join when a broadcast hash and shuffle hash joins are not possible.
Interested in learning about Broadcast Hash Join in Spark? – Click here.


4 Comments
[…] Interested in learning about Shuffle Sort Merge join in Spark? – Click here. […]
[…] Take a look at the below execution plan. Currently when you print the executed plan, you see that Spark is using Sort Merge Join. […]
[…] Take a look at the below execution plan. Currently when you print the executed plan, you see that Spark is using Sort Merge Join. […]
[…] How does Shuffle Sort Merge Join work in Spark? […]