
How to transpose a DataFrame from columns to rows in Spark?
April 27, 2023How to use SnowSQL client to work with Snowflake?
May 4, 2023Quick Introduction
Snowflake Inc. offers an advanced data platform that provides a fully self-managed service called Snowflake. This platform enables faster, more flexible data storage, processing, and analytics solutions compared to traditional offerings. Snowflake provides users with all the functionality of an enterprise analytic database, along with unique capabilities and additional special features. With Snowflake, users can enjoy a more efficient and user-friendly experience when handling data without dealing with all the behind the scenes complexities.
First, let’s answer some burning questions.
Burning Questions
What is the technology behind Snowflake?
Unlike traditional “big data” software platforms like Hadoop, the Snowflake data platform does not rely on any existing database technology. Instead, Snowflake features a completely new SQL query engine and an innovative cloud-native architecture designed from scratch.
Having said that, you can safely assume that Snowflake borrowed concepts from the open source Big Data space (Hadoop, Spark, Kafka etc) for their implementation.
Where can I find Snowflake libraries or install files?
Snowflake is not an open source product. You can’t find Snowflake libraries or install files anywhere.
So how do we install it?
Snowflake is not a packaged software offering that can be installed by a user. Snowflake manages all aspects of software installation and updates on public cloud infrastructure.
Where does Snowflake run?
Snowflake runs completely on cloud infrastructure. All components of Snowflake’s service (other than optional command line clients, drivers, and connectors), run in public cloud infrastructures like – AWS, Azure or Google Cloud. Snowflake uses virtual compute instances for its compute needs and a storage service for persistent storage of data.
Can I run Snowflake on-premise or private cloud?
Nope. Snowflake cannot be run on private cloud infrastructures (on-premises or hosted).
Now that we have answered some basic questions about Snowflake, let’s explore Snowflake by loading data and querying data.
Our Goal
Our goal is to load a Covid related dataset into Snowflake and run some basic queries in Snowflake. We will also explore some key components inside Snowflake to understand Snowflake a little bit better.
Creating a free account
Now that we know Snowflake is not open source, does it cost money to try Snowflake? No. Snowflake offers a 30 day trial with $400 work of free storage.
Go to https://signup.snowflake.com/ to create an account for free. Note: you don’t need a corporate email to create the account. But make sure to provide a valid email since you receive a link for verification to this email.
Cloud Provider
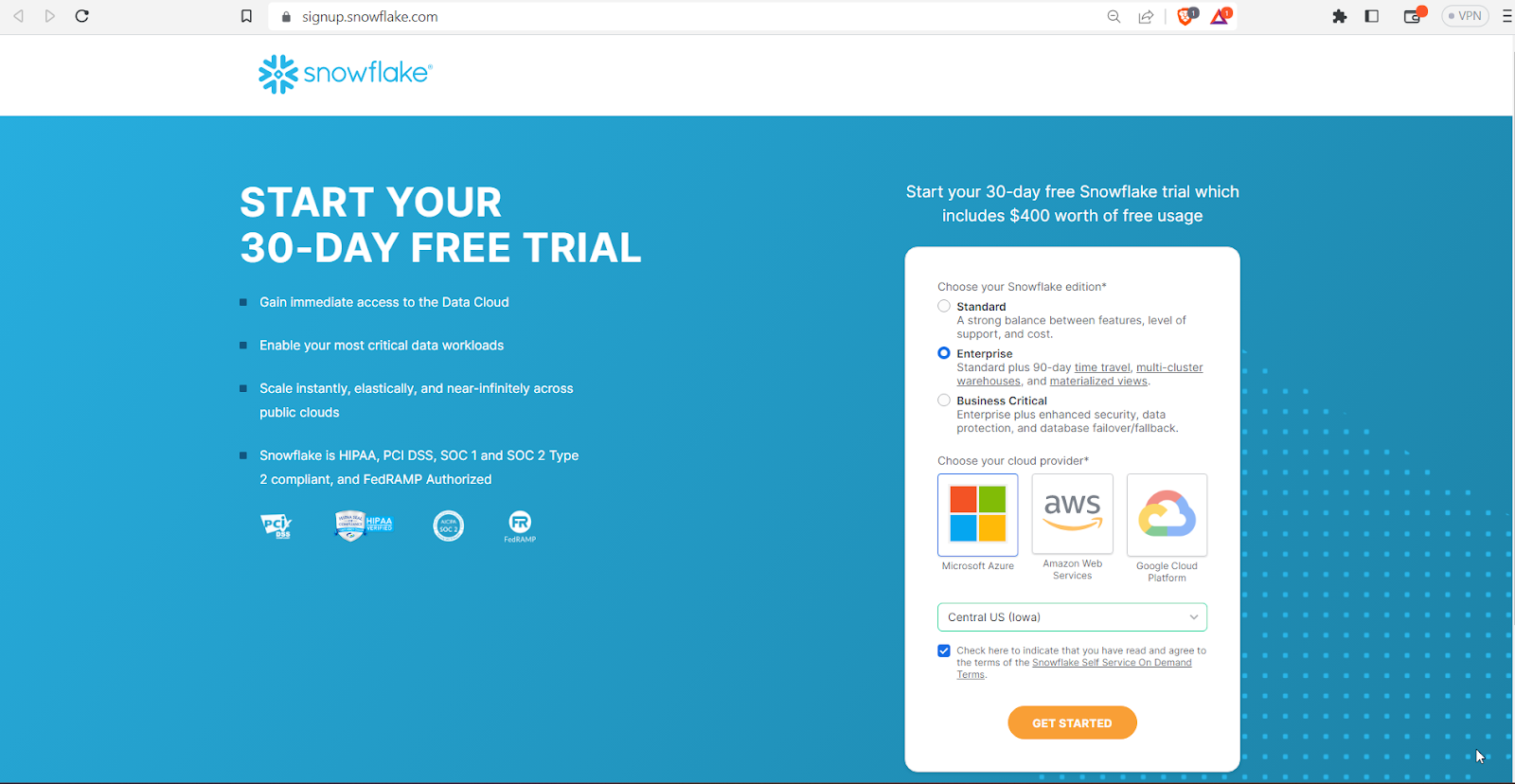
We need to make 2 selections in the next screen – Snowflake edition and Cloud Provider.
Enterprise edition is the default so we can stick with that.
We got 3 options to choose from here – AWS, Azure, Google Cloud Platform (GCP). Let’s pick Azure. Snowflake has made it really easy to work with different cloud providers. We don’t need to have an account in any of the cloud providers. Behind the scenes they will create the necessary resources on cloud and we don’t have to worry much.
Covid Dataset
Here is how the home screen looks once you login. Snowflake comes with preloaded sample data and worksheets which you can explore right away. Worksheets are very similar to Jupyter or Zepplin notebooks.

To load Covid dataset – select Marketplace from the left menu and select COVID-19 Epidemiological Data.

The dataset is Free to use. Click on Get.

The data will be loaded in a database. You can provide a name to the database or go with the default. A new database will be created If the database doesn’t exist.

That is it. The Covid dataset is now ready to use. We can run some queries against it. That’s easy!

You can see a worksheet is automatically added to query the Covid dataset which we just loaded into a database.

Working with Data
Before we query the dataset, let’s explore the database where our Covid data is loaded into.
Databases
Select Data > Databases from the left menu. Here in this screen, you can see the list of databases. The first database in the list is what was created when we loaded the Covid data.

Covid dataset has collection of different data files which are loaded into separate tables.

Querying Data
Let’s go back to the home screen and select the Covid worksheet. Here you can see the worksheet has some preloaded queries. The first query aggregates the number of Covid cases by country. Let’s select the query and execute.

Click the play button on top after selecting the query. Now the question is – where does the query run?
It runs on COMPUTE_WH (highlighted below). WH stands for warehouse. It represents a collection of compute resources.

Click on the columns in the result and you can see summary information of the selected result on the right.


Warehouse
Now that we have loaded some data and queried the data. Let’s explore warehouses. Warehouse is a collection of resources – CPU, Memory and Disk which are used to execute the queries.
Click on COMPUTE_WH on the top right to see the details of the warehouse.

In the Warehouse detail screen, you can see the size of the cluster. Our warehouse is X-Small. You can get different sizing options available and pricing here – https://docs.snowflake.com/en/user-guide/warehouses-overview

You can also see the executions in the warehouse under Query History. We will write a more detailed post on Warehouses in the future.

Conclusion
I think we can wrap up at this point here. We created a free account, loaded some dataset, queried the data and explored warehouses. You can see Snowflake has made it much easier to work with data. Lot of what happens behind the scenes is hidden – which can be seen as good as bad. As for me, I like open systems, where we can see how it works behind the scenes.
Snowflake is an interesting platform and has gained a lot of interest in the industry. So we plan to write a few more blog posts about Snowflake in the future.


1 Comment
[…] to connect and work with Snowflake. If you are new to Snowflake, we encourage you to check out our Getting started with Snowflake in less than 10 minutes post first before you continue with this […]