Changing Number Of Mappers Number of mappers always equals to the Number of splits. Having said that it is possible to control the number of splits […]
InputSplit vs Block The central idea behind MapReduce is distributed processing and hence the most important thing is to divide the dataset in to chunks and […]
JobTracker and TaskTracker JobTracker and TaskTracker are 2 essential process involved in MapReduce execution in MRv1 (or Hadoop version 1). Both processes are now deprecated in […]
NameNode and DataNode In this post let’s talk about the 2 important types of nodes and it’s functions in your Hadoop cluster – NameNode and DataNode. […]
How to change default replication factor? What Is Replication Factor? Replication factor dictates how many copies of a block should be kept in your cluster. […]
One of my close friends recently joined Microsoft in Seattle in their highly acclaimed data analysis team. I asked him what was his first assignment. He […]
This post will explain how can you approach the above question when asked in an interview. This is an open ended interview question and the interviewer […]
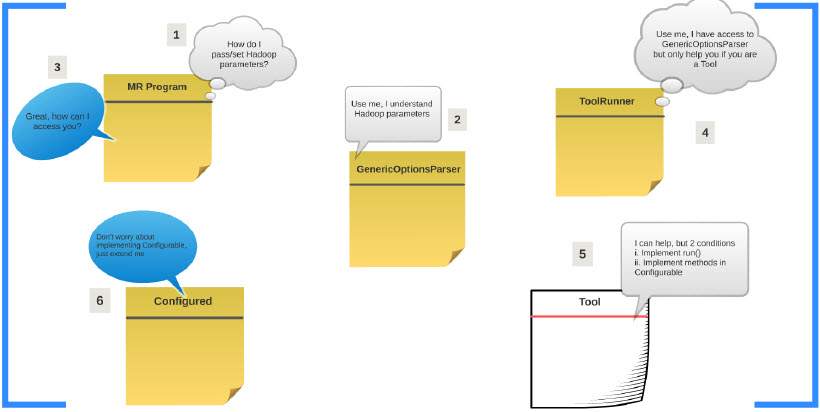
This post explains the class relationship when we use ToolRunner to run a MapReduce job. It is not really complicated but we use the below pictorial […]
This post explains how to unit test a MapReduce program using MRUnit. Apache MRUnit ™ is a Java library that helps developers unit test Apache Hadoop map […]
What is Million Song Dataset ? The Million Song Dataset is a freely-available collection of audio features and metadata for a million contemporary popular music tracks. The […]
Executions in Hadoop use the underlying logged in username to figure out the permissions in the cluster. When running jobs or working with HDFS, the user […]








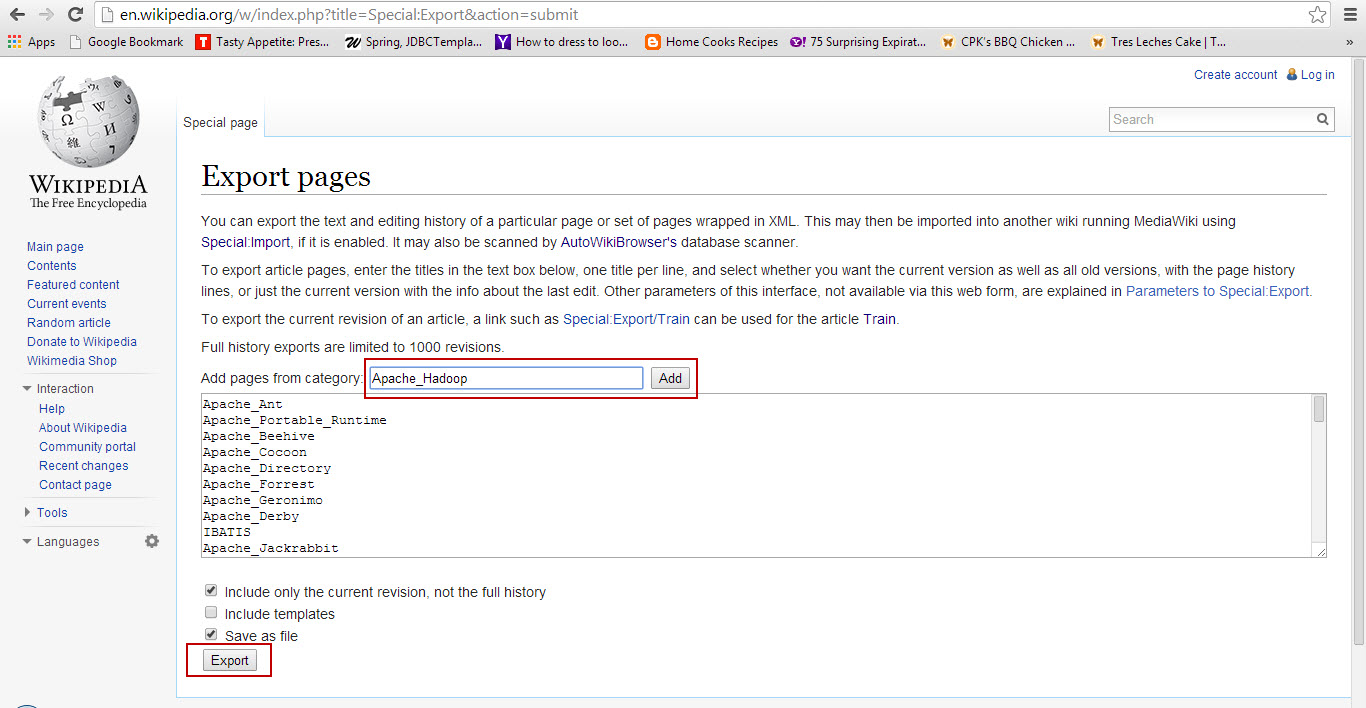
{kind=link}
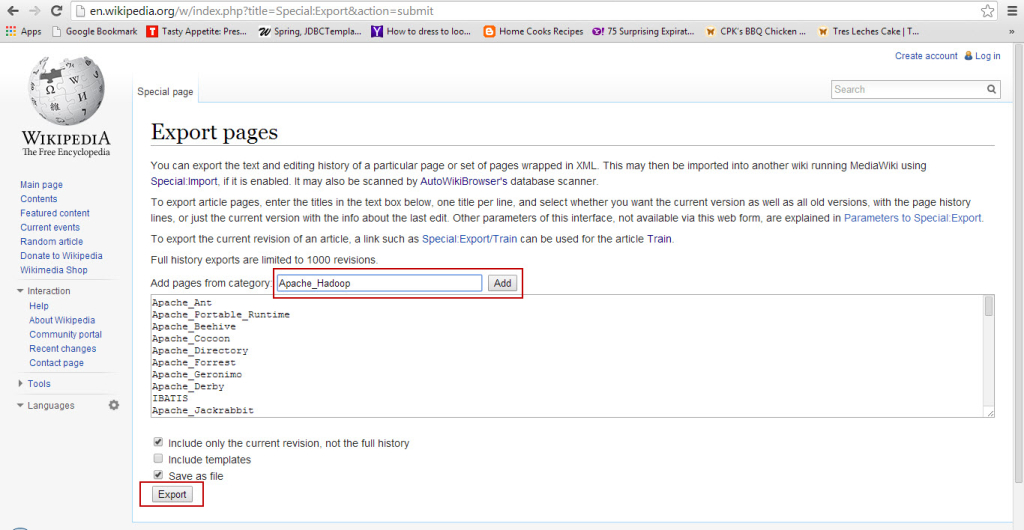{kind=link}