The easiest way to purge or delete messages in a Kafka topic is by setting the retention.ms to a low value. retention.ms configuration controls how long […]
The function of repartition and coalesce functions in Spark is to change the number of partitions on a DataFrame. Repartition Increase or decrease partitions. Repartition always […]
So you were installing Hive and ran into the below issue when Hive was trying to set up the metastore database. Exception in thread "main" java.lang.RuntimeException: […]
Hive scripts which are scheduled to run in production always take in variables. These variables are set in dynamically and you would need to pass the […]
In this post we will look at how to calculate resource allocation for Spark applications. Figuring out how to allocate resources for a Spark application requires […]
ksqlDB is an event streaming database that enables creating powerful stream processing applications on top of Apache Kafka by using the familiar SQL syntax, which is […]
Those in the industry know that one of the best techniques for catching malware using Machine Learning (ML) is only possible with distributed computing. Before showing […]
Considering building a big data streaming application? You have come to the right place. This is a comprehensive post on the architectural and orchestration of big […]
In this post we are going to look at schema evolution and compatibility types in Kafka with Kafka schema registry. With a good understanding of compatibility […]



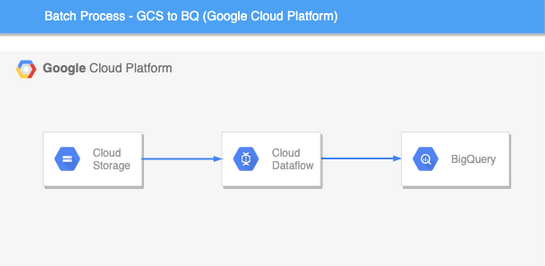
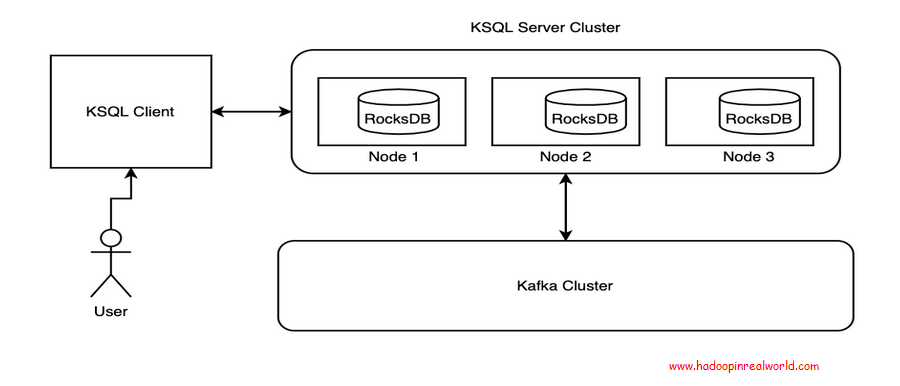

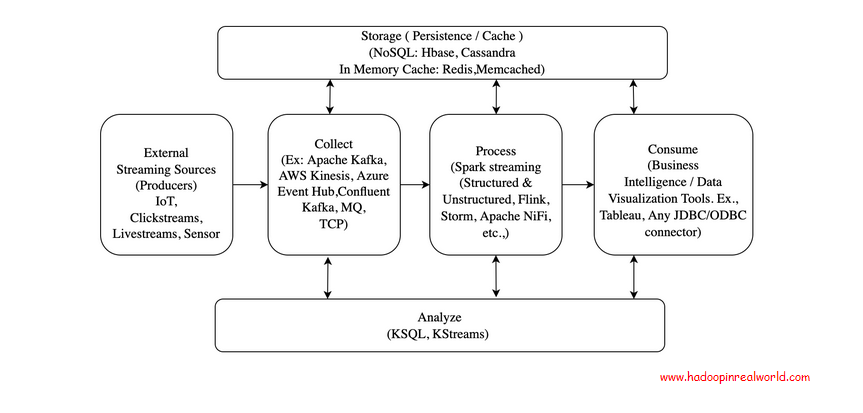

{kind=link}
{kind=link}
{kind=link}