
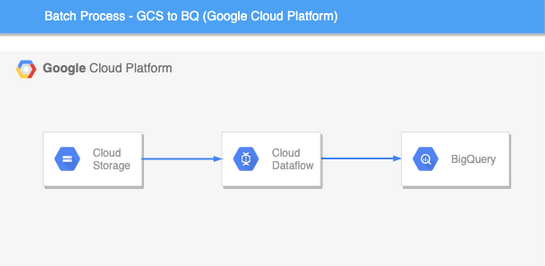
Batch Processing with Google Cloud DataFlow and Apache Beam
June 29, 2020Try Hadoop In 5 Minutes
September 20, 2020In this post we will look at how to calculate resource allocation for Spark applications. Figuring out how to allocate resources for a Spark application requires a good understanding of resource allocation properties in YARN and also resource related properties in Spark. Let’s look at both.
Interested in Spark? check out our Spark Developer In Real World course for interesting use case and real world projects in Spark
Understanding YARN Properties
It’s important to think about how the resources are requested by Spark, as it needs to fit into what YARN has available. The relevant YARN properties are:
yarn.nodemanager.resource.memory-mb controls the maximum sum of memory used by the containers on each node.
yarn.nodemanager.resource.cpu-vcores controls the maximum sum of cores used by the containers on each node.
Understanding Spark Application Properties
–executor-cores / spark.executor.cores determines number of cores or the number of concurrent tasks an executor can run.
–executor-memory / spark.executor.memory determines the heap memory per executor.
–num-executors / spark.executor.instances determines number of executors per application.
spark.executor.memoryOverhead max (384, 0.1 * spark.executor.memory)
JVMs use some off heap memory, for example for interned Strings, direct byte buffers and Python processes are spawn in this memory.
Allocating Resources
Suppose you have a cluster with 6 nodes and each node is equipped with 16 cores and 64GB of memory.
YARN Container Configurations
yarn.nodemanager.resource.memory-mb = 63 * 1024 = 64512 (megabytes) yarn.nodemanager.resource.cpu-vcores = 15
We avoid allocating 100% of the resources to YARN containers because the node needs some resources to run the OS and Hadoop daemons. In this case, we leave 1GB and 1 core for the system processes like VM overheads, OS processes.
Resources Available for Spark Application
Total Number of Nodes = 6
Total Number of Cores = 6 * 15 = 90
Total Memory = 6 * 63 = 378 GB
So the total requested amount of memory per executor must be:
spark.executor.memory + spark.executor.memoryOverhead < yarn.nodemanager.resource.memory-mb
Interested in Spark? check out our Spark Developer In Real World course for interesting use case and real world projects in Spark
Calculating Resources for Spark Application
To achieve full write throughput in HDFS so we should keep the number of core equals to 5 or less as a best practice, this is to avoid poor HDFS I/O throughput due to high concurrent threads.
Total Number Executor = Total Number Of Cores / 5 => 90/5 = 18.
We have 3 executors per node and 63 GB memory per node then memory per node should be 63/3 = 21 GB but this is wrong as heap + overhead < container/executor so
Overhead Memory = max(384 , 0.1 * 21) ~ 2 GB (roughly)
Heap Memory = 21 – 2 ~ 19 GB
On the Yarn Cluster Manager we need to make room for Application Master so we will reserve 1 executor as Application Master.
Finally
--executor-cores / spark.executor.cores = 5 --executor-memory / spark.executor.memory = 19 --num-executors / spark.executor.instances = 17
We will have 3 executors on each node except the one having an Application Master, 19GB memory available to each executor and 5 core for each executor.
Like what you are reading? You would like our free live webinars too. Sign up and get notified when we host webinars =>

