Dealing With Data Corruption In HDFS
September 6, 2015Pig vs. Hive
October 5, 2015Datanode Block Scanner
In this blog post we saw how HDFS handles and corrects data corruption in HDFS using checksum. During a write operation the datanode writing the data to HDFS verifies the checksum for the data that is being written to detect data corruption during transmission. During a read operation the client verifies the checksum that is returned by the datanode against the checksum that it calculates against the data to detect data corruption caused by disk during storage on the datanodes.
These checksum verification are very helpful but they are only done when a client attempts a read (or write) to HDFS. They don’t find corruptions prematurely before a client request a read on a corrupted data.
Every datanode periodically runs a block scanner, which periodically verifies all the blocks that is stored on the datanode. This helps to catch the corrupted block to be identified and fixed before a client request a read operation. With the block scanner service HDFS can prematurely identify and fix corruptions.
How often Block Scanner scans for corrupted blocks?
dfs.datanode.scan.period.hours in hdfs-site.xml controls how often the block scanner should run and scans for corrupted blocks. We can specify the number of hours which will act as an interval between block scanner runs. By default (in 2.7.0), dfs.datanode.scan.period.hours is set to 0 which means block scanner is disabled.
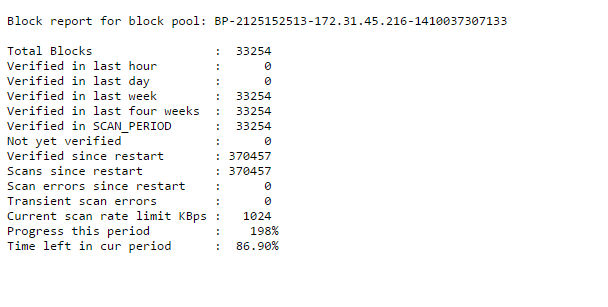
Block Scanner report
Every time block scanner runs it produces a report and it can be found at each datanodes’s URL
http://datanode:50075/blockScannerReport
Here is a sample report