Fixing org.apache.hadoop.security.AccessControlException: Permission denied
March 3, 2014
Using Million Song Dataset In Hadoop
April 19, 2014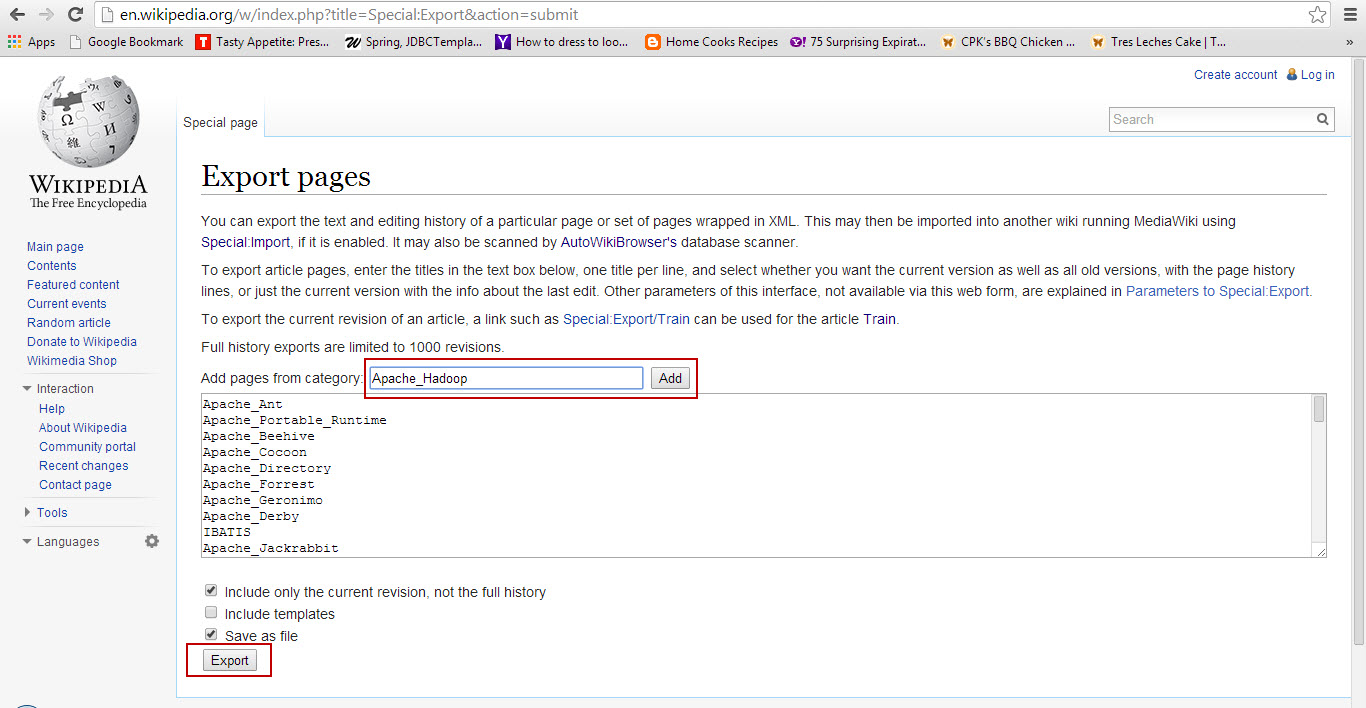
If you are new to Hadoop, you are probably tired of WordCount and want to get hands on with some real use cases. Page ranking is an excellent use case for Hadoop and it can help understand the true power of Hadoop. Wikipedia expose their pages in XML format and can be used as an input for a Page Ranking MapReduce program.
Wikipedia make XML dumps available for its pages in this location but the file sizes are in GBs and so it is very hard for new learners with few nodes in their Hadoop cluster to play with it. Below instructions will explain how to export a XML file for few pages resulting in a smaller file, which is great for testing and learning.
Get a List
Get a list of Wikipedia pages you would like to rank. For the purpose of this example, we are going to pick the following pages.
http://en.wikipedia.org/wiki/Apache_Software_Foundation http://en.wikipedia.org/wiki/Apache_Hadoop
Use the page title Apache_Software_Foundation and Apache_Hadoop for the extract below.
Extract
Go to the below URL.
http://en.wikipedia.org/w/index.php?title=Special:Export
Enter the page titles from the previous step in the space provided and hit export to download the XML file and use it as input for your Page Ranking program.
Looking for something more interesting data to analyze in Hadoop? Follow this Post to stream data from Twitter.