
Improving Performance In Spark Using Partitions
March 25, 2019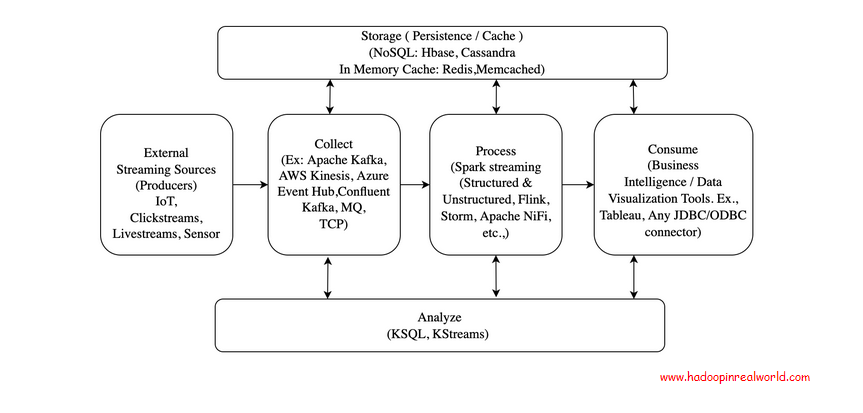
Building Big Data Streaming Pipelines – architecture, concepts and tool choices
May 4, 2020
In this post we are going to look at schema evolution and compatibility types in Kafka with Kafka schema registry. With a good understanding of compatibility types we can safely make changes to our schemas over time without breaking our producers or consumers unintentionally.
Dataset
We have a dedicated chapter on Kafka in our Hadoop Developer In Real World course. In this chapter, we stream live RSVP data from Meetup.com in to Kafka writing our very own production quality, deploy ready, producers and consumers with Spring Kafka integration. We are going to use the same RSVP data stream from Meetup.com as source to explain schema evolution and compatibility types with Kafka schema registry.
Use case and Project Setup
Let’s say Meetup.com decides to use Kafka to distribute the RSVPs. In this case, the producer program will be managed by Meetup.com and if I want to consume the RSVPs produced by Meetup.com, I have to connect to the Kakfa cluster and and consume RSVPs. For me, as a consumer to consume messages, the very first thing I need to know is the schema, that is the structure of the RSVP message. A typical schema for messages in Kafka will look like this.
{
"namespace": "com.hirw.kafkaschemaregistry.producer",
"type": "record",
"name": "Rsvp",
"fields": [
{
"name": "rsvp_id",
"type": "long"
},
{
"name": "group_name",
"type": "string"
},
{
"name": "event_id",
"type": "string"
},
{
"name": "event_name",
"type": "string"
},
{
"name": "member_id",
"type": "int"
},
{
"name": "member_name",
"type": "string"
}
]
}
The schema list the fields in the message along with the data types. You can imagine Schema to be a contract between the producer and consumer. When producer produces messages, it will use this schema to produce messages. So in this case, each RSVP message will have rsvp_id, group_name, event_id, event_name, member_id, and member_name.
Producer is a Spring Kafka project, writing Rsvp messages in to Kafka using the above Schema. So all messages sent to the Kafka topic will be written using the above Schema and will be serialized using Avro. We are assuming producer code is maintained by meetup.com. Consumer is also a Spring Kafka project, consuming messages that are written to Kafka. Consumer will also use the schema above and deserialize the Rsvp messages using Avro. We maintain the consumer project.
Problem
Meetup.com went live with this new way of distributing RSVPs – that is through Kafka. Both the producer and consumer agrees on the Schema and everything is great. It is silly to think that the schema would stay like that forever. Let’s say meetup.com didn’t feel the value in providing member_id field and removes it. What do you think will happen – will it affect consumers?
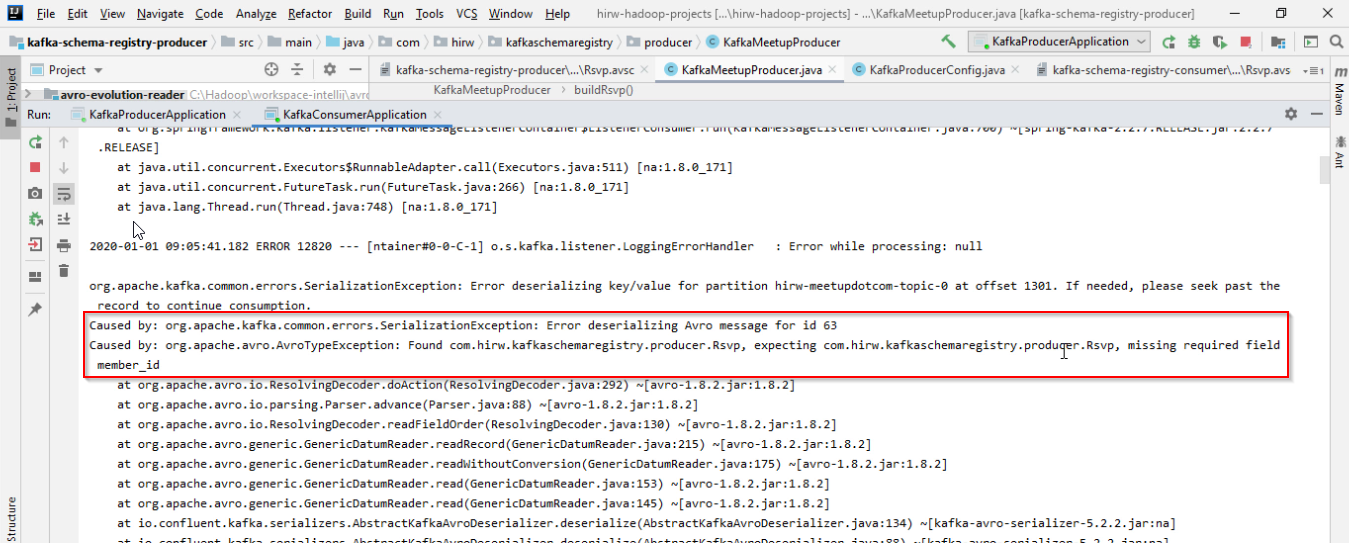
member_id field doesn’t have a default value and it is considered a required column so this change will affect the consumers. When a producer removes a required field, the consumer will see an error something like below –
Caused by: org.apache.kafka.common.errors.SerializationException: Error deserializing Avro message for id 63
Caused by: org.apache.avro.AvroTypeException: found com.hirw.kafkaschemaregistry.producer.Rsvp,
expecting com.hirw.kafkaschemaregistry.producer.Rsvp, missing required field member_id
If the consumers are paying consumers, they will be pissed off and this will be a very costly mistake. Are there ways to avoid such mistakes? Lucky for us, there are ways to avoid such mistakes with Kafka schema registry and compatibility types. Kafka schema registry provides us ways to check our changes to the proposed new schema and make sure the changes we are making to the schema is compatible with existing schemas. What changes are permissible and what changes are not permissible on our schemas depend on the compatibility type that is defined at the topic level.
There are several compatibility types in Kafka. Let’s now explore each one.
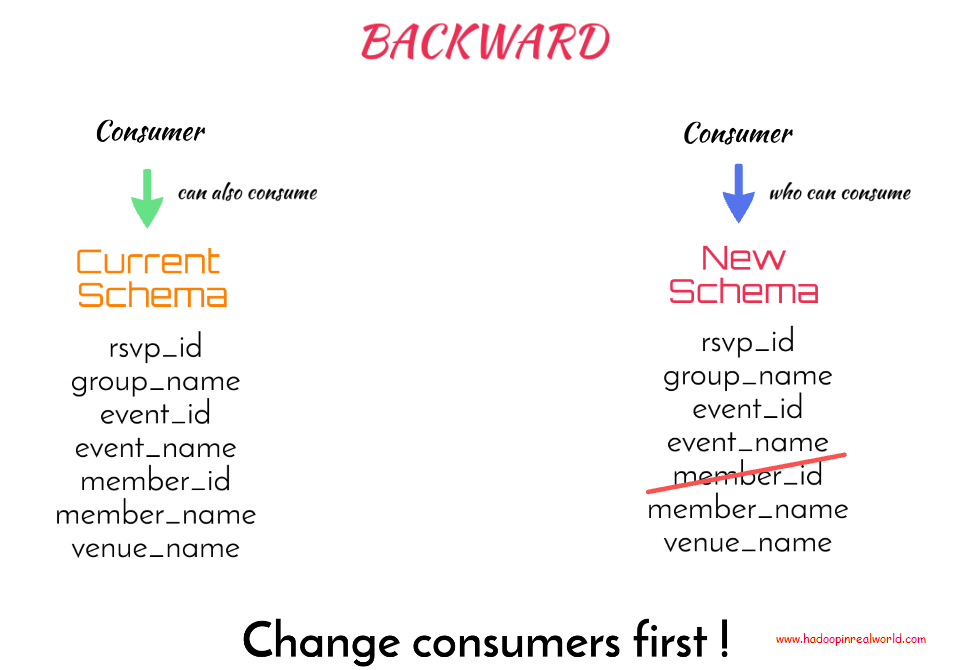
BACKWARD
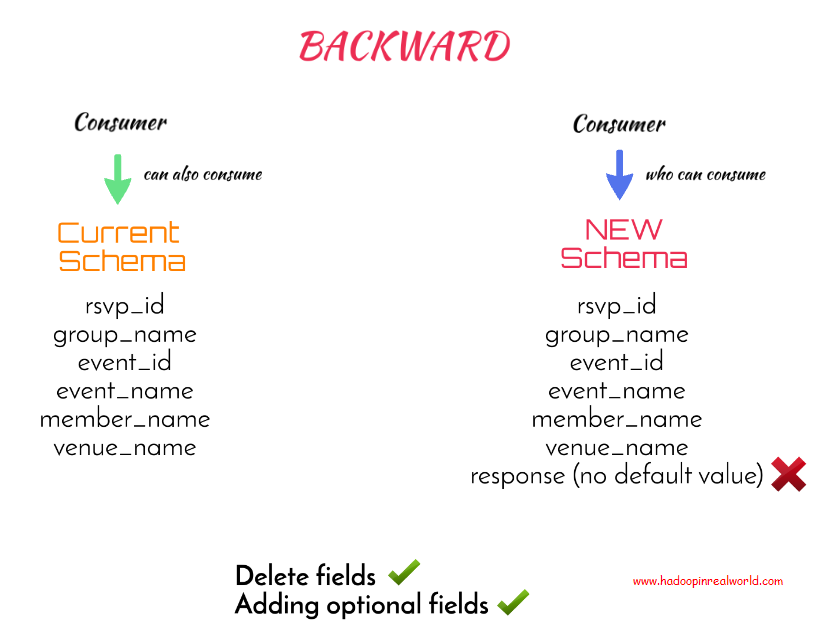
A schema is considered BACKWARD compatible if a consumer who is able to consume the data produced by new schema will also be able to consume the data produced by the current schema.
BACKWARD compatibility type is the default compatibility type for the schema registry if we didn’t specify the compatibility type explicitly. Let’s now try to understand what happened when we removed the member_id field from the new schema. Is the new schema backward compatible?
In the new schema we are removing member_id. Assume a consumer is already consuming the data produced with the new schema – we need to ask can he consume the data produced with the old schema. The answer is yes. In the new schema member_id is not present so if the consumer is presented with data with member_id, that is with the current schema, he will have no problem reading it because extra field are fine. So we can say the new schema is backward compatible and Kafka schema registry will allow the new schema.
But unfortunately this change will affect existing customers as we saw with our demonstration. So in backward compatibility mode, the consumers should change first to accommodate for the new schema. Meaning, we need to make the schema change on the consumer first before we can make it on the producer.
This is OK if you have control on the consumers or if the consumers are driving the changes to the schema. In some cases, consumers won’t be happy making changes on their side, especially if they are paid consumers. In such instances backward compatibility is not the best option.
If consumers are affected with a change why did schema registry allows the change in the first place?
Compatibility types doesn’t guarantee all changes will be transparent to everyone. It gives us a guideline and understanding of what changes are permissible and what changes are not permissible for a given compatibility type. When changes are permissible for a compatible type, with good understanding of compatible types, we will be in a better position to understand who will be impacted so we can take measures appropriately.
In our current instance removing member_id in the new schema is permissible as per BACKWARD compatibility type. Because as per BACKWARD compatibility, a consumer who is able to consume RSVP with out member_id that is with new schema will be able to consume RSVP with the old schema that is with member_id. So the change is allowed as per BACKWARD compatibility but that doesn’t mean the change is not disruptive if it is not handled properly.
Schema changes in BACKWARD compatibility mode, it is best to notify consumers first before changing the schema. In our case meetup.com should notify the consumers that the member_id will be removed and let consumers remove references of member_id first and then change the producer to remove the member_id. That’s the most appropriate way to handle this specific schema change.
In backward compatibility mode can I add a field with no default value in the new schema?
Here we are trying to add a new field named response, which is actually the user’s response of their RSVP and it doesn’t have a default value. Is this change to the schema acceptable in Backward compatibility type? What do you think?
Let’s see. With BACKWARD compatible mode, a consumer who is able to consume the data produced by new schema will also be able to consume the data produced by the current schema.
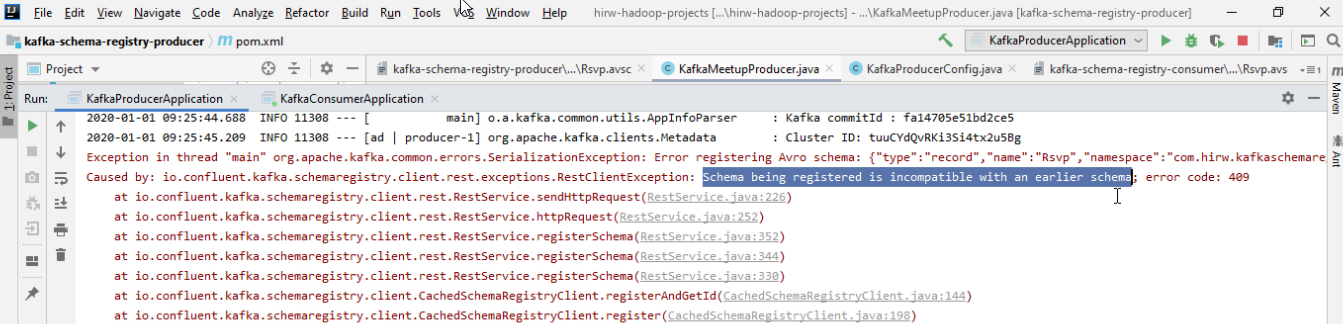
So assume a consumer is already consuming data with response which doesn’t have a default value meaning it is a required field. Now, can he consume the data produced with current schema which doesn’t have a response? The answer is NO because the consumer will expect response in the data as it a required field. So the proposed schema change is not backward compatible and the schema registry will not allow this change in the first place.
The error is very clear stating “Schema being registered is incompatible with an earlier schema”
So if the schema is not compatible with the set compatibility type the schema registry rejects the change and this is to safeguard us from unintended changes.
What if we change the field response with a default value? Will this change considered backward compatible?
Answer this – “Can a consumer that is already consuming data with response with a default value of let’s say “No response” consume the data produced with current schema which doesn’t have a response?”
The answer is YES because consumer consuming data produced with the new schema with response will substitute the default value when the response field is missing which will be the case when the data is produced with current schema.
To summarize, BACKWARD compatibility allows deleting and adding fields with default values to the schema. Unlike adding fields with default values, deleting fields will affect consumers so it is best to update consumers first with BACKWARD compatibility type.
BACKWARD_TRANSITIVE
BACKWARD compatibility type checks the new version against the current version if you need this check to be done on all registered versions then you need to use BACKWARD_TRANSITIVE compatibility type.

FORWARD
Alright, so far we have seen BACKWARD and BACKWARD_TRANSITIVE compatibility types.
But what if we don’t like the schema changes to affect current consumers? That is, we want to avoid what happened with our consumers when we removed member_id from the schema. When we removed member_id, it affected our consumers abruptly. If the consumers are paying customers, they would be pissed off and it would be a blow to your reputation. So, how do we avoid that?
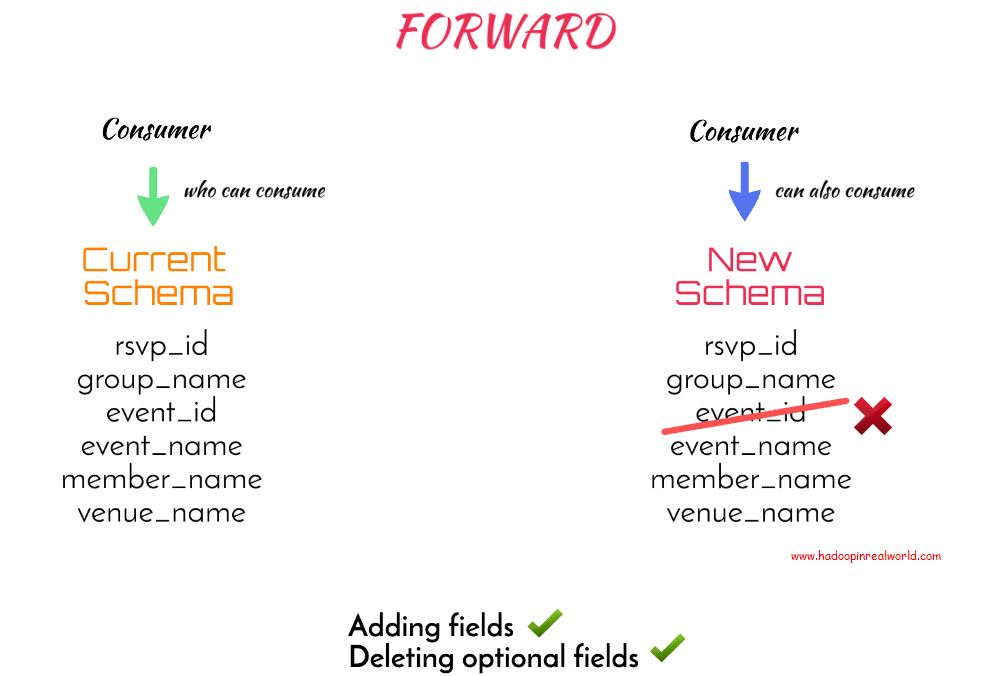
Instead of using the default compatibility type, BACKWARD, we can use the compatibility type FORWARD. A schema is considered FORWARD compatible if a consumer consuming data produced by the current schema will also be able to consume data produced by the new schema.
With this rule, we won’t be able to remove a column without a default value in our new schema because that would affect the consumers consuming the current schema. So adding fields are OK and deleting optional fields are OK too.
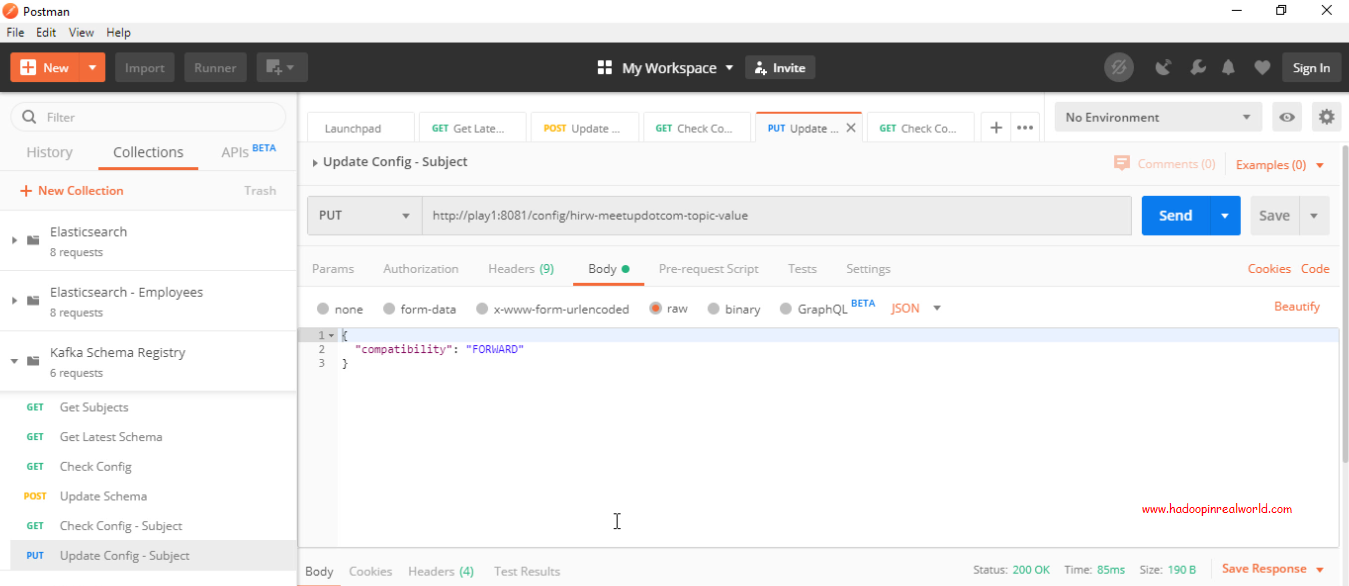
How to change compatibility type for a topic?
Issue a PUT request on the config specifying the topic name and in the body of the request specify the compatibility as FORWARD. That’s it. Let’s issue the request.
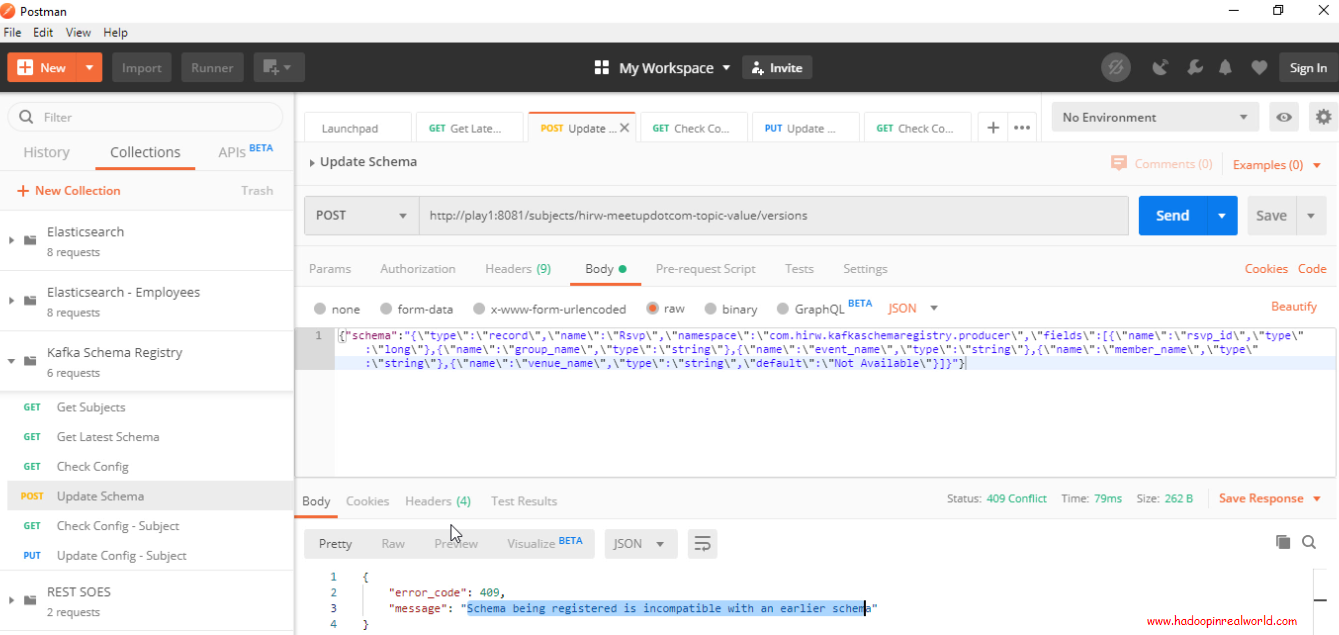
Now when we check the config on the topic we will see that the compatibility type is now set to FORWARD. Now that the compatibility type of the topic is changed to FORWARD, we are not allowed to delete required fields that is columns without default values. Let’s confirm that. Why don’t we attempt to remove the event_id field, which is a required field.
Let’s update the schema on the topic by issuing a REST command. To update the schema we will issue a POST with the body containing the new schema. Here in the schema we have removed the field event_id.
{“schema”:”{\”type\”:\”record\”,\”name\”:\”Rsvp\”,\”namespace\”:\”com.hirw.kafkaschemaregistry.producer\”,\”fields\”:[{\”name\”:\”rsvp_id\”,\”type\”:\”long\”},{\”name\”:\”group_name\”,\”type\”:\”string\”},{\”name\”:\”event_name\”,\”type\”:\”string\”},{\”name\”:\”member_name\”,\”type\”:\”string\”},{\”name\”:\”venue_name\”,\”type\”:\”string\”,\”default\”:\”Not Available\”}]}”}
See with compatibility type set to FORWARD the update actually failed. You would have received the same response even if you made changes to your code, updating the schema and pushing the RSVPs. With FORWARD compatibility type, you can guarantee that consumers who are consuming your current schema will be able to consume the new schema.
FORWARD_TRANSITIVE
FORWARD only check the new schema with the current schema, if you want to check against all registered schemas you need to change the compatibility type to, you guessed it – FORWARD_TRANSITIVE.

FULL & NONE
There are 3 more compatibility types. If you want your schemas to be both FORWARD and BACKWARD compatible, then you can use FULL. With FULL compatibility type you are allowed to add or remove only optional fields that is fields with default values. FULL checks your new schema with the current schema. If you want the new schema to be checked against all registered schemas, you can use, again, you guessed it, use FULL_TRANSITIVE. FULL and FULL_TRANSITIVE compatibility types are more restrictive compared to others.
The last compatibility type is NONE. NONE means all compatibility types are disabled. This means all changes are possible and this is risky and not typically used in production.


1 Comment
[…] If you are enjoying this post, you may also interested in learning about Kafka Schema Registry & Schema Evolution […]