
Calculate Resource Allocation for Spark Applications
July 13, 2020How to show full column content in a Spark DataFrame?
December 7, 2020Let’s do this!
We are going to do 3 things and trust us, it is going to take less than 5 minutes.
1. Login to our Hadoop cluster on AWS cloud (for free)
2. Try HDFS
3. Run a MapReduce job
Login to our Hadoop cluster on AWS cloud (for free)
You would need keys to login to our cluster. Sign up and get you the keys if you don’t have the keys yet. Follow the instructions below once you have the keys.
Host IP – 54.85.143.224
User Name – hirwuser150430
Click here if you don’t have the private key to connect to the cluster
Follow below steps if you are using Windows
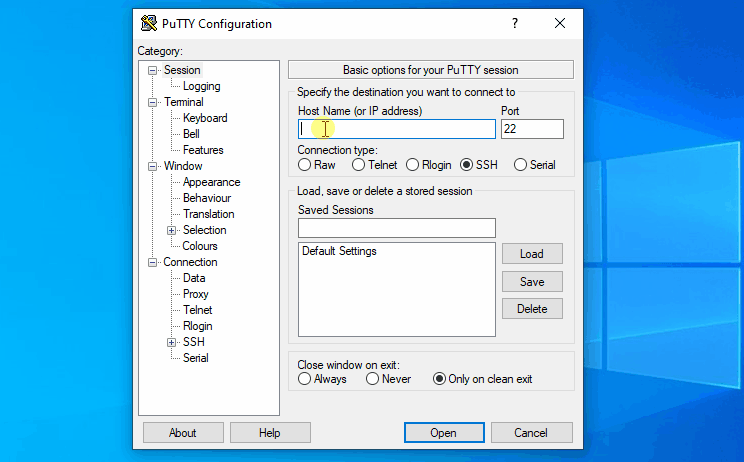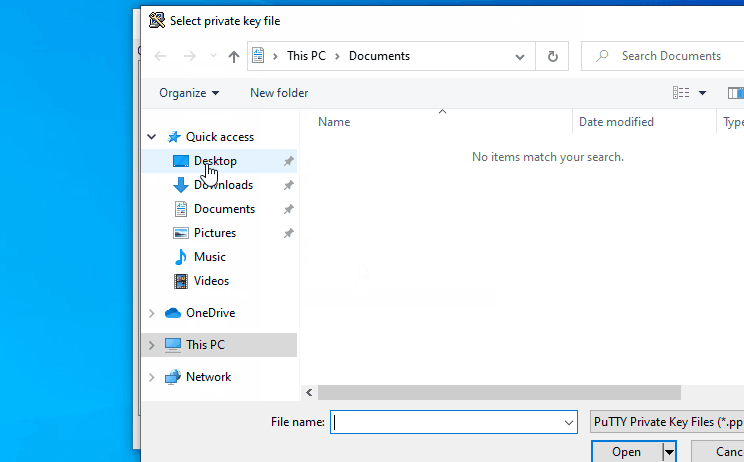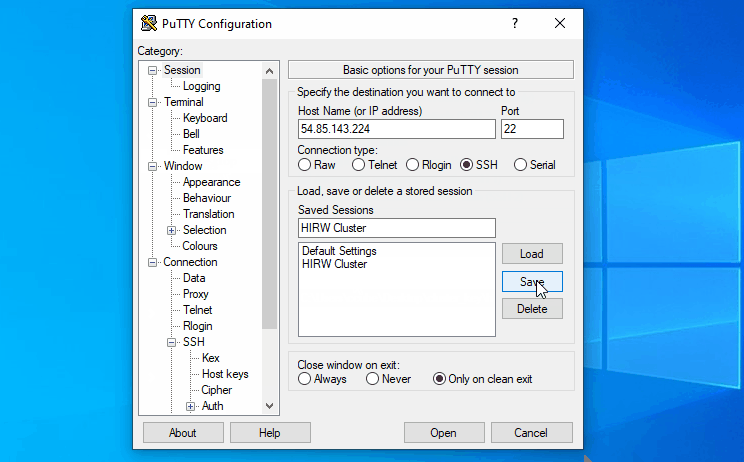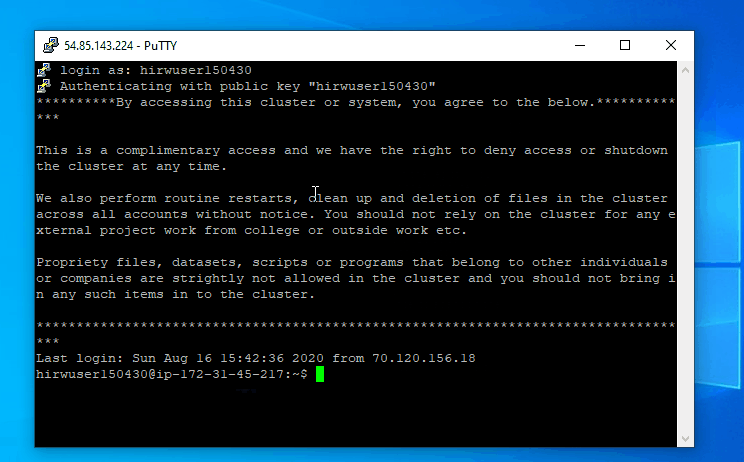
Follow below steps if you are using Linux
Switch to the directory where you have downloaded your keys.
chmod 600 hirwuser150430.pem ssh -i hirwuser150430.pem hirwuser150430@54.85.143.22

Try HDFS
Now to the fun part.
- Create a directory
- Upload a file to the directory
- Delete the directory
Create a directory
Create a directory named “my-first-hdfs-directory”. Change the directory name to your liking.
hadoop fs -mkdir my-first-hdfs-directory
Upload a file to the directory
You are now uploading a file named sample-file.csv to a directory in HDFS which you created in the previous step.
hadoop fs -copyFromLocal /hirw-starterkit/hdfs/sample-file.csv my-first-hdfs-directory
Delete the directory
Let’s now delete the directory which we created.
hadoop fs -rm -r my-first-hdfs-directory
Alright, now that we have tried HDFS, let’s now try to run a MapReduce job.
Run a MapReduce job
You are now going to calculate maximum close price of each stock from the stocks dataset. The stock dataset is under /user/hirw/input/stocks and output will be saved under output/mapreduce/stocks in HDFS.
Delete output directory
hadoop fs -rm -r output/mapreduce/stocks
Run MapReduce job
hadoop jar /hirw-starterkit/mapreduce/stocks/MaxClosePrice-1.0.jar com.hirw.maxcloseprice.MaxClosePrice /user/hirw/input/stocks output/mapreduce/stocks
View output
hadoop fs -cat output/mapreduce/stocks/part-r-00000
Congratulations! You have now tried both HDFS and MapReduce. Want to learn more? Enroll in our free Hadoop Starter Kit course. It is 100% free and we promise you will learn more about Hadoop in this free course than from paid course offered by others.
Interested in chatting with us to learn about our course offering? We are just one click away.
Please note: we work in Chicago hours and we don’t outsource support. If you find us not responding, you most likely caught us in our night time. Please leave us your email in the chat and we will get back to you as soon as we see your message.


1 Comment
[…] Try Hadoop In 5 Minutes – Hadoop In Real World […]