
Q&A Session – Spark, Flink, Cluster Sizing and more
October 18, 2017Troubleshooting Memory Issues with MapReduce Jobs
November 1, 2017ZooKeeper is a coordination service for distributed applications. Well, what the heck is that right? Glad you asked. If you are looking to understand what is ZooKeeper and to understand it’s use case or the problem ZooKeeper is trying to solve in a little bit of depth, you have come to the right place. ZooKeeper’s documentation even doesn’t do a good job of explaining what is ZooKeeper in simple terms and it’s use case. So we thought we will give it a shot.
Imagine you are a kindergarten teacher and you have 15 kids in your class. You would like to elect a class leader. You as the teacher of the class can pick a kid of your choice to be the class leader but that won’t be fair to the other kids. So you tell your kids, the kid who jumps the highest will be the class leader. I know that is lame and a terrible method to elect a class leader but nevertheless, in the class leader election process, you the teacher, became the coordinator.
Here in the class leader election process, the teacher is the ZooKeeper and the kids are distributed applications.
ZooKeeper is an open source Apache project usually installed on 3 nodes. And the 3 nodes form the ZooKeeper cluster or quorum, the ZooKeeper cluster is then used to coordinate certain activities between distributed applications. I know that is still not clear. Let’s see how ZooKeeper is used in real world.
ZooKeeper & YARN HA
In this post we will see, how ZooKeeper is used to achieve high availability in YARN? Resource Manager in YARN is a single point to failure – meaning if we have Resource Manager running on only one node and when that node fails, we have a problem and we won’t be able to run any jobs in our Hadoop cluster. To avoid Resource Manager to be a single point of failure we need to enable High Availability with Resource Manager. This means we will run another Resource Manager instance on another node in stand by mode. When the active Resource Manager fails with high availability configuration in place the stand by resource manager will take the role of the active resource manager. Now, when the active resource manager fails, we can manually failover the resource manager so the standby resource manager will become active. This means there is manual intervention involved from the Hadoop administrator to initiate the failover. In a busy and highly active production cluster, manual failover is not a great option because you will lose valuable time in contacting the administrator and initiating the failover.
The other option we have is automatic failover. We can configure ZooKeeper to do an automatic failover of the resource manager when the active resource manager fails. How does ZooKeeper help or facilitate the automatic failover? There are 2 things we want to understand here.
1. How ZooKeeper is used to elect the active resource manager when there are more than one resource managers? This is referred to as leader election.
2. How ZooKeeper handles automatic failover? That is, how does a stand by resource manager becomes active in an event the active resource manager fail.

If you have read so far, we promise you will love to hear what other things we have to say.
Leader Election
Leader election is one of the common use case for ZooKeeper. Let’s see how it works.
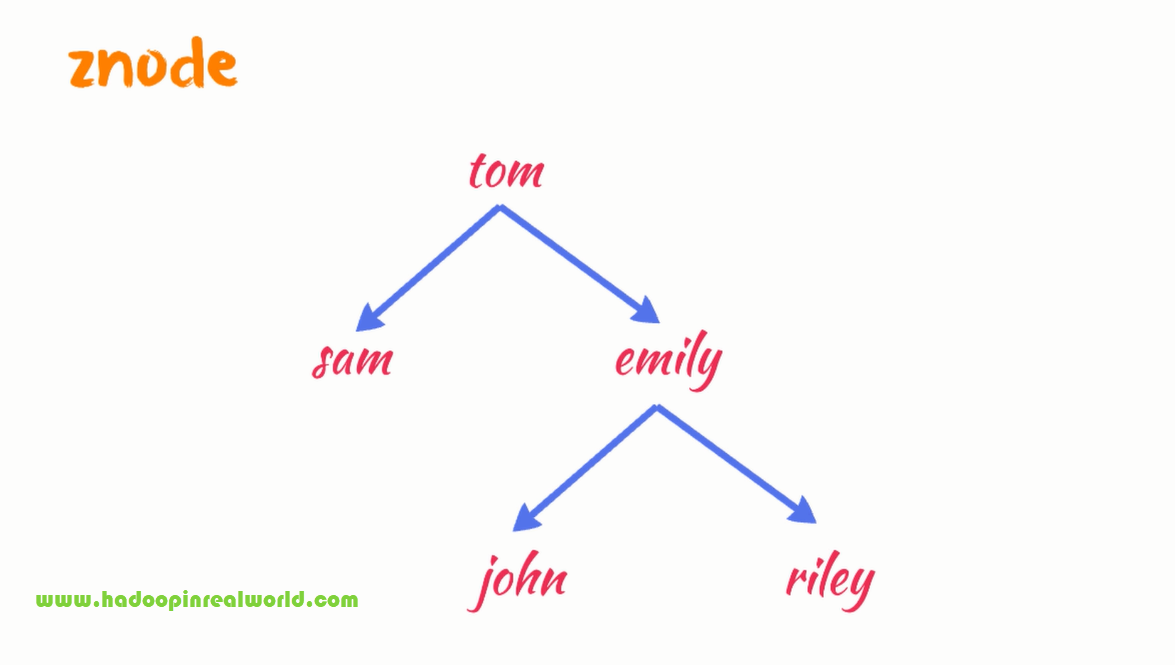
As an application using ZooKeeper you can create what is called a znode in ZooKeeper. Znodes in ZooKeeper looks like a file system structure with folders and files. For example in this illustration. tom is a znode and it has two znodes under it – sam and emily, emily has two more znodes – john and riley. We can also embed data in each znode if we like. You can not embed a lot of data. You can embed data less than 1 MB.
Let’s say we have 2 resource managers. Each resource manager will participate in the leader election process to decide who becomes the active resource manager. Resource managers use ZooKeeper to elect a leader among themselves. Let’s see how it works. Both resource mangers will attempt to create a znode named ActiveStandbyElectorLock in ZooKeeper and only one resource manager will be able to create ActiveStandbyElectorLock znode.

Whoever creates this znode first will become the active resource manager. So if resource manger 1 creates ActiveStandbyElectorLock first, it will become the active node and if resource manger 2 creates ActiveStandbyElectorLock, it will be become the active node.
Let’s say resource manger 1 created the ActiveStandbyElectorLock znode first, resource manager 2 will also attempt to create ActiveStandbyElectorLock but it won’t be able to because ActiveStandbyElectorLock is already created by resource manager 1 so resource manager 1 becomes the active resource manager and resource manager 2 becomes the stand by node and goes in to stand by mode. So far clear?
So we have now elected a leader. Resource manager 1 is the active resource manager now.
Ephemeral Node
There is an interesting thing about ActiveStandbyElectorLock znode, it is a special kind of znode. It is called an ephemeral node. Meaning if the process creating an ephemeral node loses its sesson with ZooKeeper, the znode will be deleted. Meaning when resource manager 1 goes down or losses the sesson with Zookeper ActiveStandbyElectorLock will be deleted.
Persistent Node
Resource manager 1 will also create another znode named znode named ActiveBreadCrumb. ActiveBreadCrumb znode is not an ephemeral node, it is another type of znode called persistent node meaning when resource manager 1 goes down or losses the session with ZooKeper, unlike ActiveStandbyElectorLock znode, ActiveBreadCrumb, which is a persistent znode, does not gets deleted.
Resource manager 1 will write information about itself, the host name and port of resource manager 1 in to the ActiveBreadCrumb. This way anyone can find out who is the active resource manager at any given time.
Failover
With Resource Manager 1 as the active node, everything is working good, up until one fine morning when the RAM in resource manager 1 has gone bad. So resource manager 1 went down. Now our expectation is resource manager 2 should become the active node automatically. Let’s now understand how failover from active node to standby node works.
With ZooKeeper, we can add a watch to any node, watchers are extremely helpful because if we are watching a znode and when that znode gets updated or deleted, whoever is watching the znode will get notified.
Remember, whoever creates the ActiveStandbyElectorLock ephemeral znode first becomes the active resoure manager. In our case resource manager 1 beat resource manger 2 by creating ActiveStandbyElectorLock first. When resource manager 2 tried to create ActiveStandbyElectorLock znode, it couldn’t because it was already created. So resource manager 2 realized that there is already an active resource manager elected and it became the stand by node. Before resource manager 2 becomes stand by, it will add a watch on the ActiveStandbyElectorLock znode.
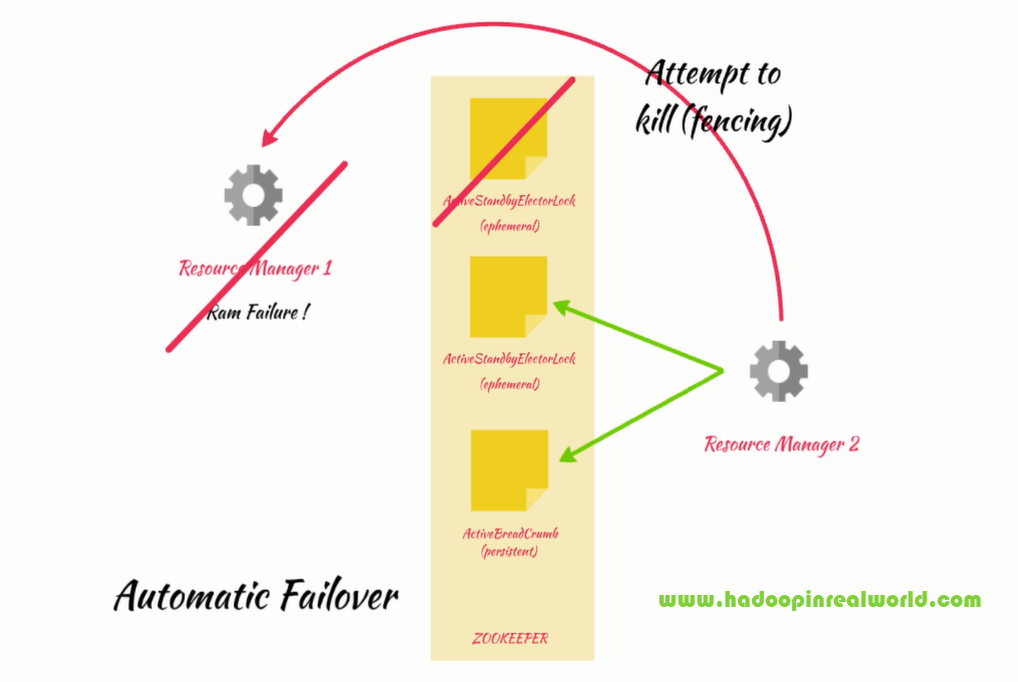
When resource manager 1 goes down due to the RAM failure, it’s session with ZooKeeper will become dead and since ActiveStandbyElectorLock is an ephemeral node, ZooKeeper will then delete the ActiveStandbyElectorLock node as soon the application who created the znode loses connection with ZooKeeper. Since resource manger 2 is watching the ActiveStandbyElectorLock node, it will get a notification stating ActiveStandbyElectorLock is gone.
Resource Manager 2 will now attempt to create ActiveStandbyElectorLock node and since it is the only one trying to create the node, it will succeed in creating the ActiveStandbyElectorLock znode and will become the active resource manager.
Fencing
A RAM failure is not recoverable but assume resource manager 1 experienced a connectivity issue with ZooKeeper for a brief moment. This will cause ZooKeeper to delete the ActiveStandbyElectorLock ephemeral znode, because for ZooKeeper it lost the session with resource manger 1 – it doesn’t matter few seconds or minutes. As soon the session is lost, ZooKeeper will delete the ActiveStandbyElectorLock ephemeral znode.
But in this case resource manager 1 is still active at least it thinks it is active. By this time resource manger 2 becomes active. We don’t want 2 resource managers thinking or acting as active at the same time, this will cause lot of issues for the applications running in the cluster and it is referred to as split brain scenario.
So before resource manager 2 becomes active it will read ActiveBreadCrumb znode to find who was the active node, in our case it will be resource manager 1 and will attempt to kill the resource manager 1 process, this process is referred to as fencing. This way we are certain that there is only one active resource manager at time. After the fencing attempt, resource manager 2 will write it’s information to the ActiveBreadCrumb znode since it is now the active resource manager.
This is how ZooKeeper is used in leader election and failover process with YARN or resource manager high availability. This same concept is applied to achieve NameNode high availability as well. So when you have multiple process or application trying to perform the same action but you need coordination between the applications so they don’t step on each other “toes” you can use ZooKeeper as a coordinator for the applications.
If you have read so far, we promise you will love to hear what other things we have to say.

